
トライ

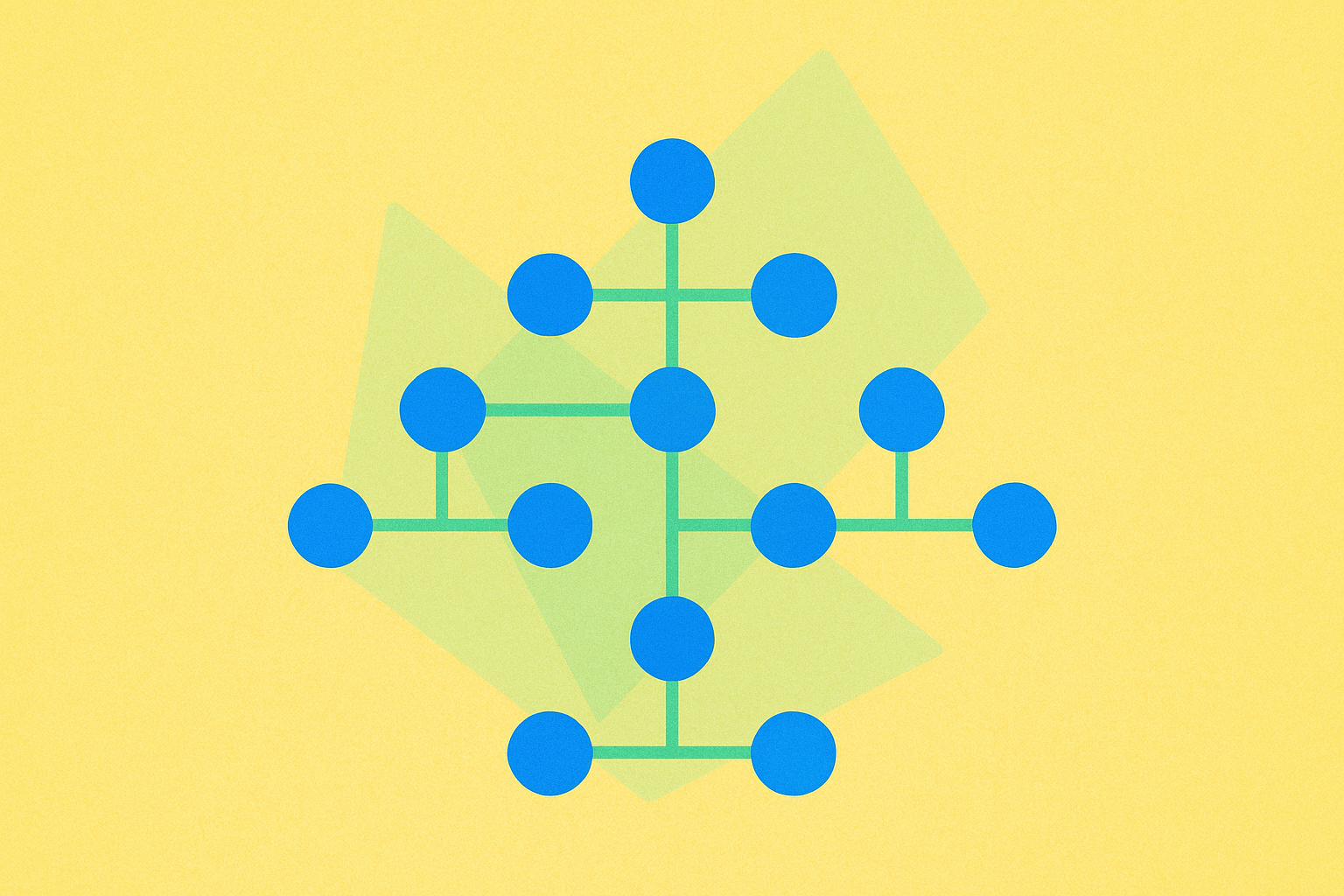
Trie(トライ、Prefix Tree)は、主に文字列をキーとした動的集合や連想配列の格納に用いられる特殊な探索木です。Binary Search Treeとは異なり、Trieの各ノードは直接的なキー情報を保持せず、ノードの木構造内の位置がキーを定義します。この特徴により、文字列操作に際して非常に高い効率性を発揮します。
近年のデータ検索・保存技術の発展により、Trieのような効率的なデータ構造の重要性が増しています。例えば、Googleのオートコンプリート機能ではTrieを活用し、入力された文字に応じて検索候補を即座に表示しています。この仕組みはユーザー体験を向上させるだけでなく、関連データの検索時間や計算資源の最適化にも寄与します。Trieは格納する文字列間で共通のプレフィックス(接頭辞)を共有できるため、大規模な語彙や巨大な文字列データの取り扱いに極めて高いメモリ効率を発揮します。
歴史的背景と発展
Trieの基本概念は、フランスの計算機科学者René de la Briandaisが1959年に発表した論文で初めて示されました。彼はこの木構造型データ構造の基礎理論を提唱しています。その後、1960年にEdward Fredkinが「trie」という名称を「retrieval(検索)」から派生させて命名し、データ検索の主目的を強調しました。Trieは誕生以来、検索クエリの最適化や大規模データの効率的処理を目的に大きく発展を遂げてきました。
デジタル革命と近年のデータ生成量の増加により、Trieは学術的な関心から実用的な計算基盤へと変化しました。膨大なテキストデータを扱う現場では、Trieの特性――検索キーの長さに依存したプレフィックス検索の高速性――が重宝されています。Trieはスペルチェックやワードゲーム、データベースインデックス、ネットワークルーティングなど様々な専門用途にも応用・最適化されています。
技術分野での応用
Trieは、独自の構造と複雑なデータセット処理の効率性から、ソフトウェア開発や情報技術分野で広く利用されています。主要用途のひとつがオートコンプリートやテキスト予測機能であり、現代の検索エンジン、モバイルキーボード、テキストエディタの根幹となっています。これらのシステムはTrieを活用し、ユーザー入力に基づいた候補語の探索を瞬時に行い、リアルタイムで提案を表示します。
テキスト処理以外にも、TrieはIPルーティングアルゴリズムの実装において重要な役割を担います。ネットワークルーターではTrieを利用し、IPアドレスとネットワークの高速マッチングを実現しています。特に最長一致検索によって、データパケットの最適な経路選択が可能となります。これにより、アドレス長に対して対数時間でルックアップが可能となり、転送遅延を最小限に抑えます。
バイオインフォマティクス分野でもTrieは重要です。Trieベースのアルゴリズムにより、膨大なゲノムデータセットからパターンや部分配列、変異の迅速な検索が可能となります。DNA配列の特定が高速化したことで、個別医療や進化生物学、疾患診断研究が加速しています。Trieはまた、辞書実装やシンボルテーブル、テキスト処理系の文字列マッチングアルゴリズムにも広く利用されています。
市場への影響と投資
主要テクノロジー企業によるTrieデータ構造の導入は、市場全体や投資環境に大きな影響をもたらしています。Trieの普及により、膨大なデータを高速・高精度で処理できるソフトウェアが次々と開発され、従来より大幅に効率化されています。こうした効率向上は、特にビッグデータ分野の企業にとって競争優位性の源泉となります。
Trieベースの最適化による経済的メリットは、業界全体にも波及しています。Trieを活用する企業は、サーバー要件やレスポンスタイムの低減による運用コスト削減、顧客満足度・維持率の向上など明確な成果を得ています。こうしたメリットが、Trie技術への投資を活性化させており、AIや機械学習プラットフォームでは効率的なデータ構造がアルゴリズム性能の決め手となるため注目度が高まっています。
Trie関連技術への投資は近年急速に拡大しており、高度なデータ処理需要を背景に、ベンチャーキャピタルや企業資本がTrie最適化を活用した検索システム、自然言語処理ツール、データベース管理ソリューションの開発企業に流入しています。この動向は、Trieの効率的なデータ構造が市場リーダーシップを左右する戦略的資産であることを示しています。
今後の動向とイノベーション
Trieの将来は極めて明るく、効率性・拡張性・新たな計算課題への適用性の向上を目指した研究が進められています。圧縮Trie(Radix Tree/Patricia Trie)や三分探索Trieなどの革新により、メモリ消費を抑えつつ検索性能を維持・向上できるバリエーションが登場しており、メモリ制約環境や組み込みシステムでも適用しやすくなっています。
IoTの普及とクラウドコンピューティングの高度化に伴い、Trieはこれら技術が生み出す膨大なデータ管理・検索により重要な役割を果たします。IoTデバイスは時系列データやログ、センサー情報を生成し続けるため、効率的なインデックスや検索が不可欠です。TrieはデバイスIDや地理コードなど階層型データフォーマットへの対応力が高いことも特徴です。
機械学習・AI分野でもTrieを活用した革新が進行しています。語彙管理や単語埋め込みの検索など自然言語処理のボトルネック解消にTrieを取り入れる動きや、不揮発性メモリ・特殊プロセッサとTrieの組み合わせによる高性能化など、新たな可能性が広がっています。これらの進展はデータ処理技術全体に革新をもたらし、情報の格納・検索・解析方法を根本から変える可能性を秘めています。
まとめ
Trieデータ構造は、現代コンピューティングに不可欠な強力かつ多用途のツールとして、多様な業界でデータ検索やシステム効率向上に大きく貢献しています。複雑な文字列キーを持つ大規模データセットの効率的処理能力は、検索エンジン、ネットワークルーティング、バイオインフォマティクスなどにおいて必須です。Trieの共通プレフィックス共有機能はメモリ効率と高速検索を両立し、データ量の増加が進む現代でますます重要性を増しています。
データ量・複雑性の増大に伴い、Trieの存在意義はさらに高まり、関連分野の技術進化や投資を牽引しています。Trieのバリエーションや最適化が進化し続けていることは、60年以上前に考案されたこのデータ構造の根強い価値を示しています。プラットフォームごとのTrie実装が必ずしも明記されていなくとも、取引アルゴリズム、金融データ処理、リアルタイム分析システム等への応用は今後ますます一般化するでしょう。Trieの基本原理――効率的なプレフィックスマッチ、高度な階層構造、迅速な検索――は、現代のデータ集約型アプリケーションのニーズと完全に一致し、今後も長期的に重要な役割を果たし続けます。
FAQ
Trie(Prefix Tree)とは?基本原理は?
TrieはPrefix TreeまたはDictionary Treeとも呼ばれ、効率的な文字列保存・検索のための順序付き木構造です。文字列間の共通プレフィックスを共有してストレージ容量を削減し、各ノードは文字と子ノードの参照を持つことで、迅速なプレフィックス検索・挿入を可能にします。
TrieとHash Tableの利点と欠点は?
Trieはプレフィックス共有により文字比較を減らし、文字列操作のクエリ・挿入が高速です。一方、可変長キーではメモリ消費が多くなりがちです。空間効率よりも時間効率を重視する構造です。
Trieによるオートコンプリート・検索候補の実装方法は?
Trieはプレフィックスツリー構造により、入力文字列長mに対してO(m)の時間で一致検索が可能です。ノードに文字を格納し、葉ノードで単語終了を示すことで、素早いオートコンプリートや検索候補表示を実現できます。
Trieの主な実用シーンは?
Trieはオートコンプリート、スペルチェック・修正、NGワード検出・フィルタ、プレフィックスカウント、単語統計、最大XOR演算など効率的な2進数クエリにも幅広く利用されています。
基本的なTrieデータ構造の実装方法は?
ノードクラスにハッシュテーブルと単語終了フラグを持たせ、各単語を文字ごとにTrieへ順次挿入します。既存のプレフィックスを共有することでストレージ効率を高めます。
Trieの時間・空間計算量は?
Trieの挿入・検索操作はO(N)(Nは文字列長)、空間計算量はO(α^n)(αは文字集合サイズ)です。

ブロックチェーンの基礎:初心者向けの仕組み入門

ブロックチェーン開発分野でコアデベロッパーが築くキャリアパス

ブロックチェーン開発者としてのキャリアを探る:必要なスキルとチャンス

ブロックチェーン開発分野でキャリアをスタート
ブロックチェーンの基礎知識:その仕組み

インドのWeb3の未来を支える—コミュニティおよび教育への取り組み

イージーバンク振込:英国ユーザーがアカウントに資金を入金するための迅速で安全な方法
Tensor FoundationがTNSR価格高騰の中、マーケットプレイスおよびNFTシリーズを買収

コインの作成方法:詳細ガイド

Jasmy Coinのパートナーシップ:戦略的アライアンスの全貌
ループリングは$100に到達する可能性があるか
