
Trie

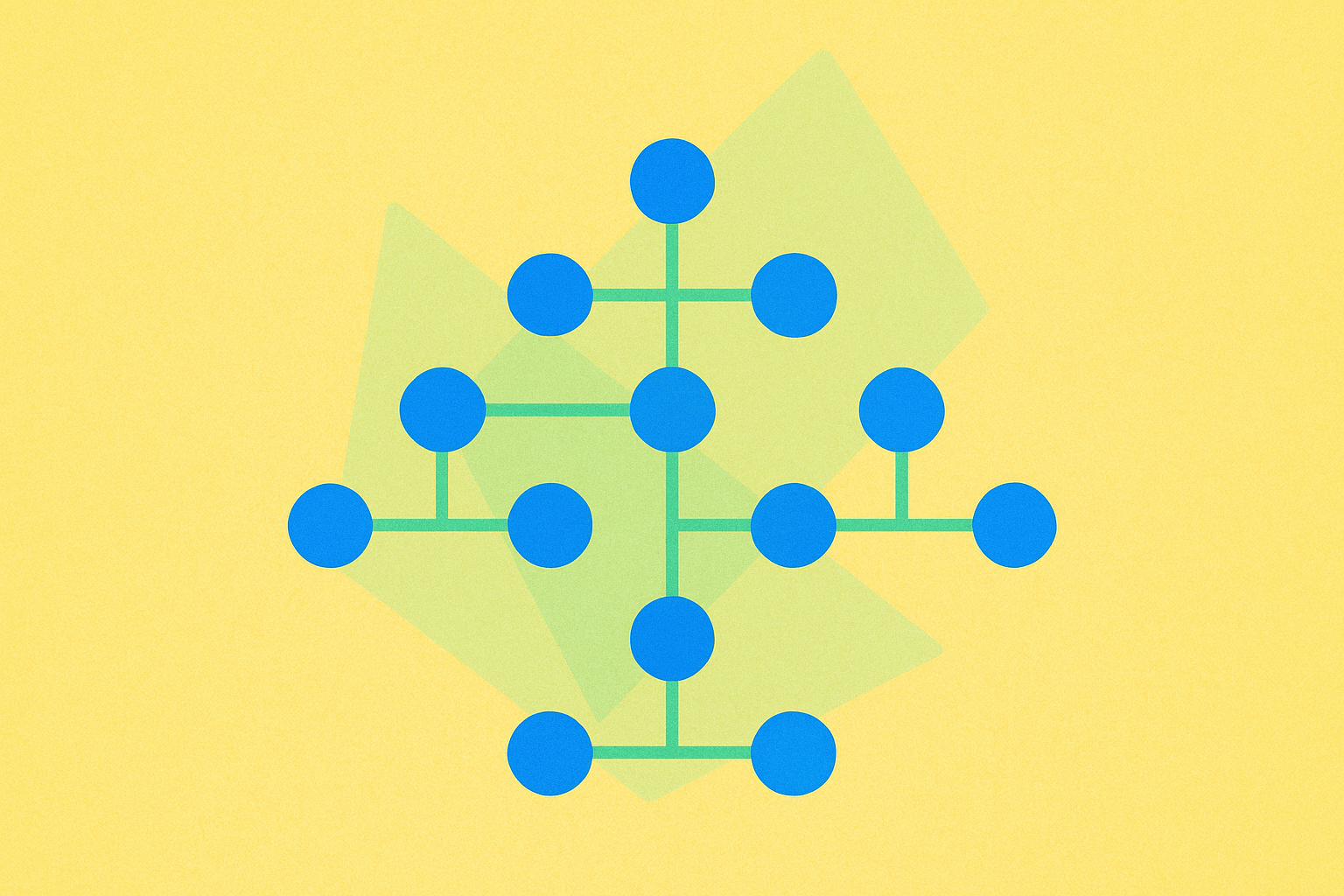
Uma trie, também designada por árvore de prefixos, é uma estrutura de árvore de pesquisa especializada utilizada para armazenar conjuntos dinâmicos ou arrays associativos em que as chaves são, habitualmente, cadeias de texto. Ao contrário das árvores binárias de pesquisa, os nós de uma trie não armazenam diretamente a chave associada; é a posição do nó na árvore que define a respetiva chave, tornando esta estrutura particularmente eficiente para operações baseadas em texto.
Os mais recentes avanços na recuperação e armazenamento de dados vieram realçar a importância fundamental de estruturas eficientes como as tries. Por exemplo, a funcionalidade de preenchimento automático da Google tira partido das tries para prever e apresentar consultas de pesquisa com base nos primeiros caracteres introduzidos pelos utilizadores. Esta implementação não só melhora a experiência do utilizador, ao disponibilizar sugestões instantâneas, como também optimiza o processo de pesquisa, ao reduzir o tempo e os recursos computacionais necessários para apresentar resultados relevantes. A capacidade da trie de partilhar prefixos comuns entre cadeias de texto armazenadas revela-se extremamente eficiente em termos de memória em aplicações que lidam com grandes vocabulários ou extensos conjuntos de dados textuais.
Contexto Histórico e Desenvolvimento
O conceito de trie foi apresentado pela primeira vez num artigo inovador de 1959, da autoria do cientista informático francês René de la Briandais, que introduziu os princípios fundamentais desta estrutura de dados baseada em árvores. O termo "trie" foi posteriormente cunhado por Edward Fredkin em 1960, derivando da palavra "retrieval" para destacar a sua finalidade principal nas operações de recuperação de dados. Desde então, a trie tem evoluído significativamente, impulsionada sobretudo pelo seu papel essencial na optimização de pesquisas e na gestão eficiente de grandes volumes de dados.
A revolução digital e o crescimento exponencial da geração de dados nas últimas décadas transformaram as tries de uma curiosidade académica num componente indispensável da infraestrutura informática contemporânea. À medida que as organizações passaram a lidar com volumes crescentes de dados textuais, as propriedades únicas da trie — sobretudo a capacidade de realizar pesquisas baseadas em prefixos num tempo proporcional ao comprimento da chave de pesquisa, e não ao número de chaves armazenadas — tornaram-se cada vez mais valiosas. Esta evolução conduziu à adaptação e optimização das tries para múltiplas aplicações especializadas, desde corretores ortográficos e jogos de palavras a indexação de bases de dados e protocolos de encaminhamento em redes.
Aplicações em Tecnologia
As tries são largamente empregues no desenvolvimento de software e nas tecnologias de informação devido à sua estrutura distinta e extraordinária eficiência no tratamento de conjuntos de dados complexos. Uma das principais aplicações reside em funcionalidades de preenchimento automático e previsão de texto, presentes em motores de pesquisa, teclados móveis e editores de texto. Estes sistemas recorrem a tries para percorrer rapidamente possíveis terminações de palavras segundo a introdução do utilizador, proporcionando sugestões em tempo real que aumentam a produtividade.
Para além do processamento de texto, as tries desempenham um papel essencial na implementação de algoritmos de encaminhamento de IP, facilitando a correspondência rápida de endereços IP com as respetivas redes. Nos routers de rede, as tries permitem uma eficiente correspondência do prefixo mais longo, fundamental para determinar o percurso ótimo dos pacotes de dados na internet. Esta estrutura possibilita pesquisas em tempo logarítmico relativamente ao comprimento do endereço, assegurando uma latência mínima no encaminhamento.
Outro importante domínio de aplicação é a bioinformática, onde as tries são utilizadas para sequenciação e análise genómica eficientes. Os investigadores usam algoritmos baseados em tries para pesquisar rapidamente vastos conjuntos de dados genéticos, identificando padrões, subsequências e mutações. A capacidade de localizar rapidamente sequências de ADN específicas em grandes bases de dados genómicos acelerou a investigação em medicina personalizada, biologia evolutiva e diagnóstico de doenças. As tries são ainda empregues em implementações de dicionários, tabelas de símbolos e diversos algoritmos de correspondência de cadeias de texto que suportam sistemas de processamento textual.
Impacto de Mercado e Investimento
A adoção de estruturas de dados trie por grandes empresas tecnológicas teve um impacto significativo no mercado tecnológico e no panorama de investimento. Esta disseminação impulsionou o desenvolvimento de soluções de software mais rápidas e eficientes, capazes de processar grandes volumes de dados com maior rapidez e precisão. Estes ganhos de eficiência são especialmente relevantes para empresas do setor de big data, onde a capacidade de recuperar e analisar informação rapidamente representa uma vantagem competitiva substancial em mercados dominados pela tecnologia.
As repercussões económicas das optimizações baseadas em tries vão além das organizações individuais, abrangendo setores inteiros. Empresas que tiram partido das tries na sua infraestrutura de dados beneficiam frequentemente de custos operacionais reduzidos, graças à diminuição das necessidades de servidores e aos tempos de resposta mais curtos, o que se traduz numa maior satisfação e retenção de clientes. Estes benefícios concretos têm atraído um interesse de investimento significativo em tecnologias baseadas em tries, sobretudo em plataformas de inteligência artificial e machine learning, onde estruturas de dados eficientes são fundamentais para o desempenho dos algoritmos.
O investimento em tecnologias trie tem vindo a crescer substancialmente nos últimos anos, impulsionado pela crescente procura de capacidades de processamento de dados mais sofisticadas. O capital de risco e o investimento corporativo têm sido canalizados para startups e empresas estabelecidas que desenvolvem sistemas de pesquisa avançados, ferramentas de processamento de linguagem natural e soluções de gestão de bases de dados que dependem de implementações trie otimizadas. Esta tendência reflete o reconhecimento de que estruturas de dados eficientes como as tries não são meros detalhes técnicos, mas sim ativos estratégicos que podem determinar a liderança de mercado em setores intensivos em dados.
Tendências Futuras e Inovações
O futuro das tries na tecnologia apresenta-se extremamente promissor, com investigação contínua dedicada a aumentar a eficiência, escalabilidade e aplicabilidade perante novos desafios computacionais. Inovações como tries comprimidas (radix trees ou Patricia tries) e tries de pesquisa ternária ilustram como esta estrutura fundamental continua a evoluir para responder às exigências da computação contemporânea. Estas variantes reduzem o consumo de memória mantendo, ou até melhorando, a performance na pesquisa, tornando-as adequadas para ambientes com limitações de memória e sistemas embebidos.
À medida que a Internet das Coisas (IoT) se expande e a computação em nuvem evolui, espera-se que as tries assumam um papel ainda mais crucial na gestão e pesquisa dos enormes volumes de dados gerados por estas tecnologias. Os dispositivos IoT produzem fluxos contínuos de dados temporais, registos de eventos e leituras de sensores que exigem mecanismos de indexação e recuperação eficientes. As estruturas baseadas em trie são especialmente adequadas à natureza hierárquica e baseada em prefixos de muitos formatos de dados IoT, desde identificadores de dispositivos a códigos de localização geográfica.
As novas aplicações em machine learning e inteligência artificial também estão a estimular a inovação nas tries. Os investigadores exploram como as tries podem acelerar operações em redes neuronais, sobretudo em tarefas de processamento de linguagem natural, onde a gestão do vocabulário e as pesquisas de embeddings de palavras constituem gargalos de desempenho. A integração de tries com novas arquiteturas de hardware, como memória não volátil e unidades de processamento especializadas, promete desbloquear novos níveis de desempenho. Estas evoluções poderão dar origem a inovações revolucionárias na tecnologia de processamento e gestão de dados, com potencial para transformar a forma como armazenamos, pesquisamos e analisamos informação em múltiplos domínios de aplicação.
Resumo
Em conclusão, a estrutura de dados trie constitui uma ferramenta poderosa e polivalente na computação moderna, com aplicações transversais a inúmeros setores que visam melhorar processos de recuperação de dados e a eficiência dos sistemas. A sua capacidade de processar eficazmente grandes volumes de dados com chaves textuais complexas torna-a indispensável em áreas como motores de pesquisa, encaminhamento em redes e bioinformática. A propriedade exclusiva da trie de partilhar prefixos comuns entre chaves armazenadas proporciona eficiência de memória e tempos de pesquisa reduzidos, características cada vez mais valiosas à medida que o volume de dados cresce.
Com o aumento do volume e da complexidade dos dados, espera-se que a relevância das tries cresça paralelamente, influenciando o desenvolvimento tecnológico e o investimento em setores correlacionados. A evolução contínua de variantes e optimizações demonstra a pertinência duradoura desta estrutura de dados, concebida há mais de seis décadas. Embora a implementação específica de tries em determinadas plataformas nem sempre seja documentada de forma explícita, é altamente provável e cada vez mais frequente a sua utilização no aperfeiçoamento de algoritmos de negociação, processamento de dados financeiros e sistemas de análise em tempo real. Os princípios fundamentais das tries — correspondência eficiente de prefixos, organização hierárquica e recuperação célere — alinham-se com as necessidades das aplicações modernas intensivas em dados, garantindo a sua importância no panorama tecnológico dos próximos anos.
FAQ
O que é uma Trie (Árvore de Prefixos)? Qual o seu princípio básico?
A Trie, também conhecida como árvore de prefixos ou árvore de dicionário, é uma estrutura de árvore ordenada para armazenamento e recuperação eficiente de cadeias de texto. Partilha prefixos comuns entre cadeias para reduzir o uso de memória. Cada nó contém um carácter e referências para os nós filhos, permitindo pesquisas e inserções rápidas com base em prefixos.
Quais são as vantagens e desvantagens da Trie em comparação com as Hash tables?
A Trie proporciona consultas e inserções mais rápidas em operações com cadeias de texto graças à partilha de prefixos, o que reduz o número de comparações. Contudo, consome mais memória, especialmente com chaves de comprimento variável. Assim, troca-se espaço por eficiência temporal.
Como implementar preenchimento automático e sugestões de pesquisa recorrendo a uma Trie?
A Trie utiliza uma estrutura de árvore de prefixos para corresponder rapidamente prefixos, com complexidade temporal O(m), sendo m o comprimento da cadeia de entrada. Os caracteres são armazenados nos nós, com marcação do fim das palavras nos nós folha, o que permite sugestões e preenchimento automático rápidos.
Quais os cenários de aplicação mais comuns para a Trie na prática?
A Trie é amplamente usada em preenchimento automático, correção e verificação ortográfica, deteção e filtragem de palavras sensíveis, contagem de prefixos, estatísticas de palavras e consultas binárias eficientes, como operações de máximo XOR.
Como implementar uma estrutura de dados Trie básica?
Crie uma classe de nó com uma hash table e um indicador de fim de palavra. Percorra cada palavra e insira os caracteres sequencialmente na Trie, partilhando prefixos já existentes para optimizar o armazenamento.
Quais são as complexidades temporal e espacial da Trie?
A Trie apresenta complexidade temporal O(N) para inserção e pesquisa, onde N é o comprimento da cadeia. A complexidade espacial é O(α^n), sendo α o tamanho do conjunto de caracteres.

Blockchain Simplificado: Guia para Iniciantes sobre o Seu Funcionamento

Explorar oportunidades profissionais em desenvolvimento blockchain para Core Developers

Explorar uma Carreira como Blockchain Developer: Competências e Oportunidades

Impulsione a sua carreira em desenvolvimento Blockchain
Fundamentos de Blockchain: Funcionamento

Impulsionar o Futuro Web3 na Índia: Iniciativas Comunitárias e de Formação

Transferências Bancárias Simples: o método rápido e seguro para os utilizadores do Reino Unido financiarem a sua conta
A Tensor Foundation adquiriu o marketplace e a série de NFT numa altura em que o preço de TNSR está a registar uma forte valorização

Como criar uma moeda: guia completo

Parcerias Jasmy Coin: Apresentação de Alianças Estratégicas
O Loopring vai alcançar os 100$
